

AI Agents & The Invisible Cost of Forgetting
How AI Agents Are Quietly Collapsing Under Their Own Memory


Every intelligent system faces the same question a human mind does:
What do you choose to remember?
For humans, forgetting is an act of mercy.
For machines, it’s an act of survival.
As large language models evolve into autonomous agents , juggling thousands of files, messages, and micro-decisions , the constraint is no longer what they can think, but what they can hold in mind.
And the choices they make about memory - when to compress, what to keep, what to discard - quietly determine whether they perform like assistants or collapse like amnesiacs.
This is the unspoken frontier of AI design: Context Compression.
Not the engineering of intelligence, but the architecture of attention.
1. The Irreversible Compression Paradox
The simplest form of forgetting is summarization — turning long histories into short notes. But this convenience hides a devastating flaw.
(P.S. This is one of those philosophical reasons why, even after coming across so many YouTube videos and summarisation tools, I’m still not in favour of using them. They make you unaware of the context , of why that information existed in the first place.)
Once you compress, you cannot always go back.
Every summarisation assumes you know which details will matter later.
But in multi-step reasoning, that assumption breaks almost instantly.
As engineers at Manus discovered, the act of compression itself becomes a prediction problem - one that no model can solve perfectly.
You cannot foresee which sentence, observation, or variable will unlock understanding ten steps later. Yet systems must compress proactively, before that future arrives.
So they face an impossible trade-off:
Save tokens, or save truth.
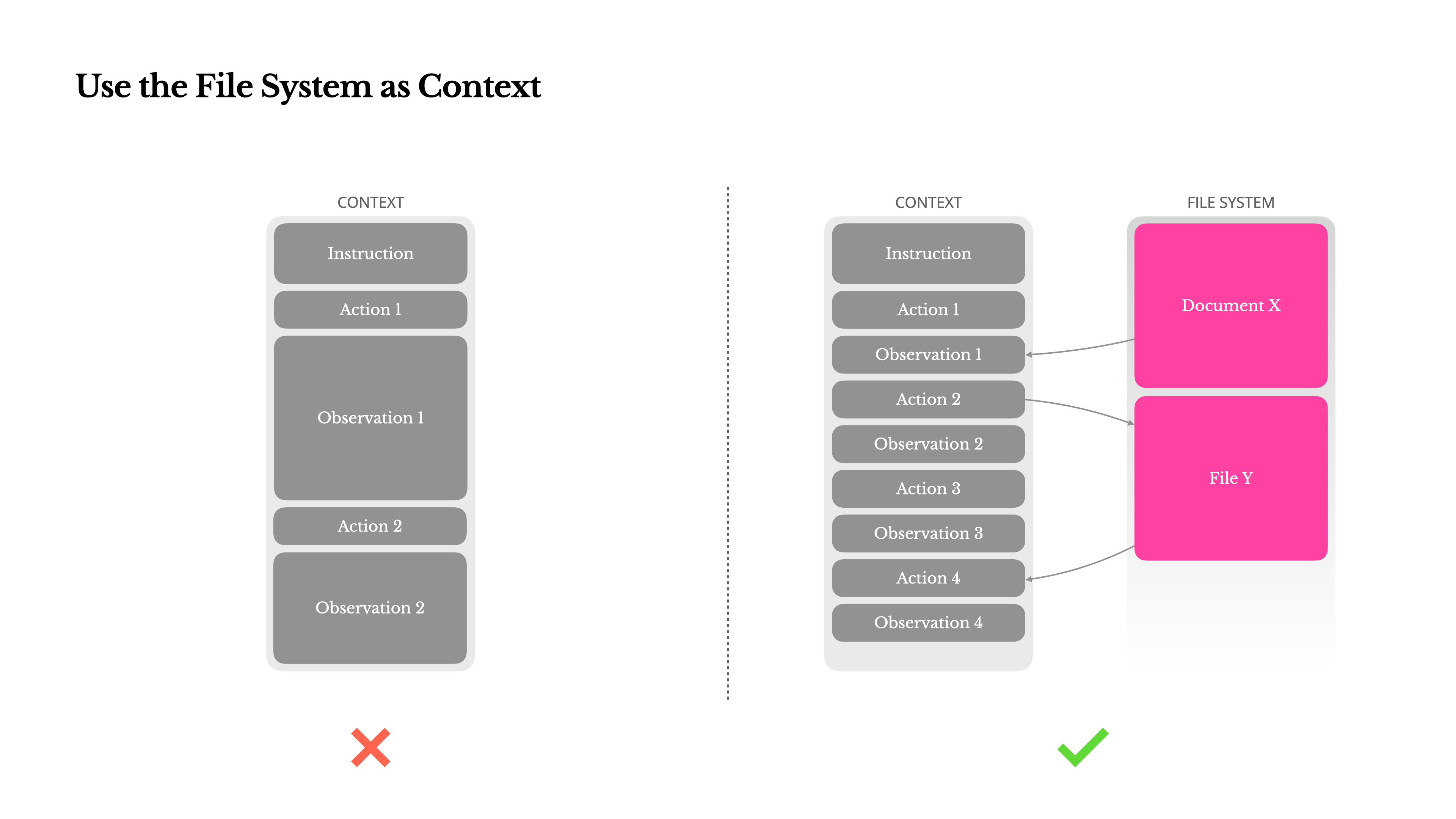
Manus’s elegant workaround - treating the file system as “unlimited, restorable context” - isn’t just an engineering decision. It’s a philosophical one.
They refuse to forget irreversibly. Instead of summarising, they refer: URLs instead of web bodies, paths instead of contents.
They choose reversibility over efficiency.
And in that choice lies a quiet lesson for every AI team:
Intelligence is not just about knowing - it’s about preserving the possibility of knowing again.
2. The Cache as a Measure of Mind
Every agent has a rhythm - a sequence of thoughts it repeats.
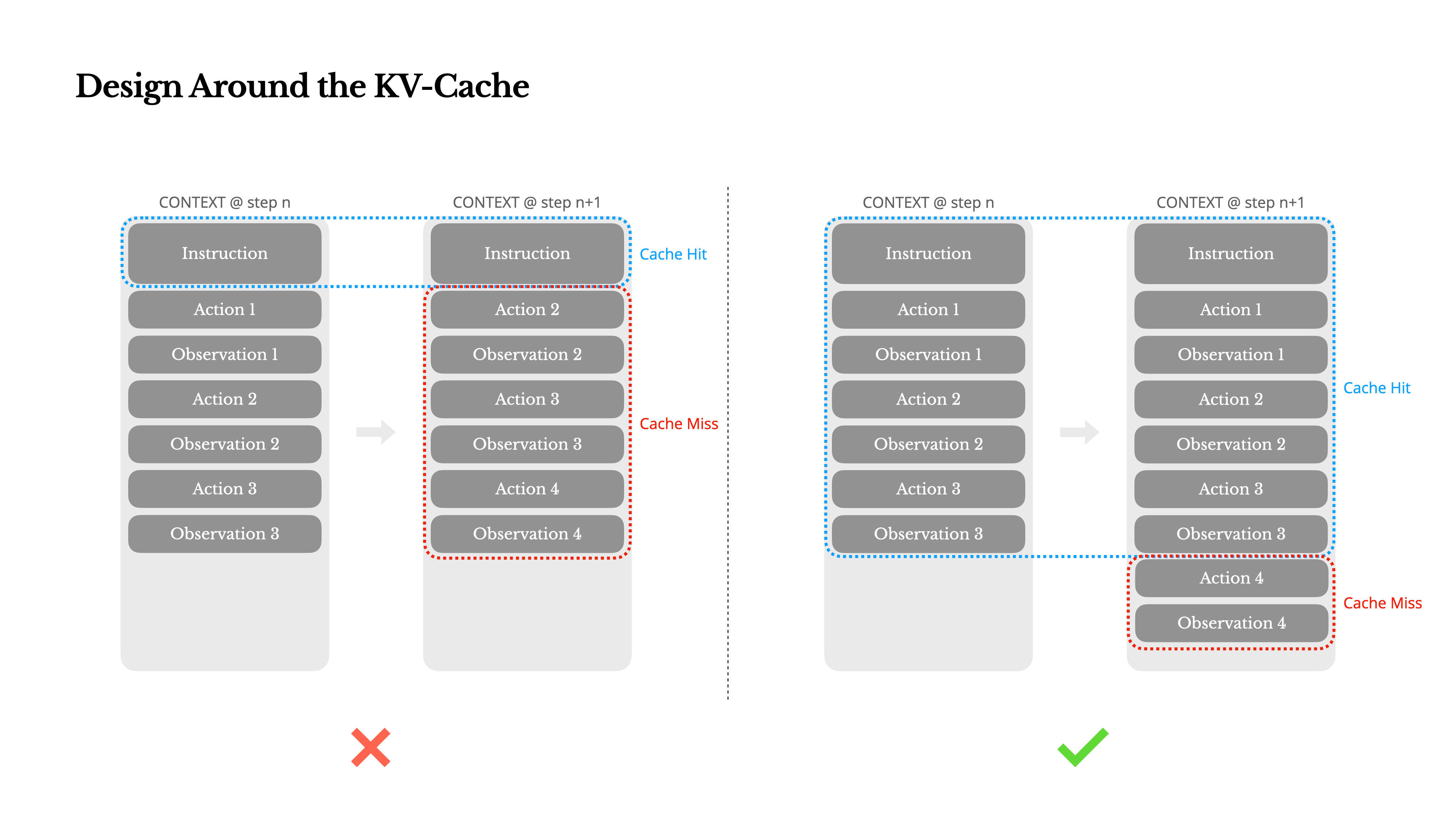
In production systems, this rhythm manifests as cache reuse.
When the same prompt prefix or state recurs, caching allows the model to “remember” without recomputing.
This might sound mundane. It’s not.
Cache hit rate has become the real heartbeat of scalable cognition.
A stable cache doesn’t just cut latency or cost; it preserves cognitive continuity.
A model with stable prompts behaves more predictably, reason more consistently, and costs exponentially less.
Perturb those prompts - say, by overzealous compression - and the illusion of continuity collapses.
You’ve taught the machine to forget its rhythm.
The lesson is counterintuitive:
Aggressive compression can make intelligence dumber and more expensive.
Optimization at the request level - the obsession with shaving off tokens - often destroys optimization at the task level.
In human terms, it’s like interrupting yourself mid-thought to rephrase every sentence - exhausting, redundant, incoherent.
3. The Cliff of Diminishing Returns
Every engineer believes in “bigger is better” — larger context windows, larger models, larger memories.
But context length has a shadow: attention diffusion.
Beyond a certain threshold - roughly 30,000 tokens for most modern models - performance doesn’t degrade gradually. It collapses.
The middle of the context becomes a cognitive void, where information goes to die.
Claude Sonnet 4.5 even shows signs of “context anxiety” - hallucinating shortcuts when it thinks it’s running out of space, even when it’s not.
Like a student who starts rushing answers near the end of an exam.
The irony is brutal:
More context can make models less intelligent.
The engineers who grasp this treat context not as a bucket to fill, but as a landscape to navigate - pruning, folding, and reshaping thought so that focus, not fullness, drives performance.
Here’s a small video , that explains this effect and implications even more deeply :
(Source : Research Paper - Lost in the Middle: How Language Models Use Long Contexts)
4. Proactive vs. Reactive Memory
The “Proactive vs. Reactive” distinction isn’t about whether to compress context, but when and how agents make memory management decisions:
Reactive Memory: Threshold-triggered compression that happens when forced (hitting token limits, time boundaries)
Proactive Memory: Intelligence-driven compression that happens when appropriate (task phase transitions, natural breakpoints)
The core tension: Reactive approaches treat compression as a consequence of capacity constraints, while proactive approaches treat it as a strategic cognitive operation.
(Source - Factory AI : Context Compression Blog)
Most AI systems compress reactively: they wait until the memory overflows, then summarise the past.
But by then, the damage is done.
The model has already spent tokens re-reading irrelevant noise.
Proactive compression → phase-based memory → flips that logic.
When a task phase ends, the agent “closes the loop” on that mental context, condensing lessons before moving on.
Manus does this through something deceptively simple: todo.md files that act as cognitive checkpoints. (Source : Manus AI : Context Engineering for agents)
Each note says: “This is done. Archive it. Focus ahead.”
It’s not just better engineering , it’s cognitive hygiene.
The same way humans declutter their minds by journaling, these agents manage their attention to stay sane.
5. The Completeness–Coherence Trade-off
Retrieval-Augmented Generation (RAG) was meant to solve the context problem , to fetch only the relevant fragments, not the whole.
But new benchmarks suggest the opposite: for codebases, legal documents, and dense information, whole-context reasoning outperforms fragmented retrieval.
Why? Coherence.
Fragments break relationships between ideas.
The model stops seeing systems and starts seeing snippets.
The industry’s fixation on “smart retrieval” may be systematically eroding understanding - like teaching someone a language one word at a time.
The truth is nuanced.
Full context wins for stable, relationship-heavy domains.
Fragmented retrieval wins for dynamic, exploratory tasks.
And the best systems , human or machine , know when to switch.
6. The True North: Tokens per Task
Across all these patterns lies a unifying principle:
Minimize tokens per task, not per request.
A model that compresses aggressively per API call might seem efficient, but when that causes it to re-fetch or re-summarize information later, total cost skyrockets.
The optimization target isn’t the micro , it’s the macro.
Not how efficiently one thought is expressed, but how coherently the whole thinking process unfolds.
This is where context compression stops being a technical question and becomes a cognitive one.
You’re no longer managing data. You’re managing attention.
Not optimizing storage , optimizing continuity of thought.
The Larger Reflection: Designing Machines That Remember Wisely
Every design decision about context , every compression, every cache, every retrieval rule encodes a philosophy of memory.
Do we trust the system to decide what’s worth keeping?
Do we value reversibility over efficiency?
Do we design for the single call, or for the arc of the conversation?
The answers will shape not just the economics of AI, but its psychology.
Because intelligence, whether human or artificial, is not defined by what it knows ,
but by what it refuses to forget.